Расскажу про небольшую утилиту командной строки Linux, которая может быть полезна при написании скриптов, либо обработке каких-либо файлов. Речь пройдёт про утилиту cut. У неё не так много параметров, что позволяет её успешно использовать, не ужасаясь возможностям, которые непременно придётся вспоминать или гуглить. Как это обычно у меня бывает, к примеру, с awk или sed.
Cut позволяет выделять фрагменты текстовой строки. Я чаще всего использую два параметра -d и -f. Первый указывает символ разделитель слов в строке, а второй - номера фрагментов, которые нужно вывести. Чтобы быстро понять принцип работы, приведу условный пример с простой строкой:# echo "dima,vova,vasya,peter,sergey" | cut -d ',' -f 2,4vova,peter
Я указал, что разделитель запятая и вывел 2 и 4 слово. В общем случае выводить отдельные столбцы удобнее через awk, но только в том случае, когда они чётко разделены между собой пробелами. Вот эти две команды будут равнозначны, но как по мне awk проще и нагляднее:
# echo "dima vova vasya peter sergey" | cut -d ' ' -f 2,4# echo "dima vova vasya peter sergey" | awk '{print $2,$4}'vova peter
Если же используется какой-то другой символ в качестве разделителя, команда cut очень удобна. Например, если надо как-то обработать файл /etc/passwd, что бывает не редко. Там значения разделены двоеточиями. Выведем имена пользователей и оболочку, которую они используют:
# cut -d ':' -f 1,7 /etc/passwdroot:/bin/bash
bin:/sbin/nologin
Либо просто выводим пользователей системы:
# cut -d ':' -f 1 /etc/passwdИногда бывает нужно заменить выходной разделитель на какой-то другой символ. Например, пробел. Делается это так:
# cut -d ':' -f 1,7 /etc/passwd --output-delimiter='_'root /bin/bash
bin /sbin/nologin
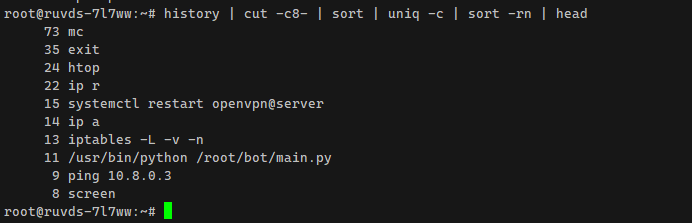
Ещё одна полезная возможность команды cut - обрезать какой-то символ в строке. При этом можно задать, начиная с какого символа мы будет отображать информацию. Это актуально для файлов или списков, где в начале строки есть какие-то лишние символы, которые надо убрать. Например, если в терминале посмотреть список history, то видно, что само название команды начинается только с 8-го символа. До этого идут пробелы и порядковый номер команды в списке истории. Можно всё это вырезать и отобразить только команду:
# history | grep git | cut -c8-Таким образом очень просто составить список наиболее популярных команд:
# history | cut -c8- | sort | uniq -c | sort -rn | headС помощью cut в скриптах часто проверяют версию ядра, разрядность, тип процессора и т.д.:
# uname -a | cut -d " " -f 34.18.0-240.8.1.el8_3.x86_64
# uname -a | cut -d " " -f 12x86_64
# cat /proc/cpuinfo | grep "name" | cut -d : -f2 | uniqIntel(R) Core(TM) i5-2500K CPU @ 3.30GHz
Отправить комментарий